systems design capstone
horizontally scaling
The whole concept for the systems design capstone was to inherit legacy code, A/B test between noSQL and SQL database, optimize query times, deploy app onto aws, horizontally scale, benchmark rps (request per seconds), optimize, load-balance, cache, and at the end of it be able to sustain 10,000 clients per second. Sound like a handful? kind of is, but when you break it down into chunks, it’s manageable.
databases - hmm so relational or non-relational?
in the end, databases are chosen based on use case. do we need relation or are we optimizing for speed. should we introduce ORMS or not? how can we optimize query times?

the testing
the two that i opted to test for were mongoDB and postgresQL. mongo being the non relational while postgres being the relational.
keeping all constants equal i began throwing queries at both databases. during this, i realized how much adding that extra ORM layer began slowing my times in relation to inputting the queries into my CLI.
running a query like the one below had about a 1.5 second difference between the shell and with the ORM. though it may seem trivial, when there’s 10,000 clients accessing your site at once, every milliseconds counts
explain analyze select * from related where gender = ‘w’ and category = ‘joggers’ order by _id desc limit 50;
RAW QUERIES
--------------------------------------------------------
PostgresQL mongoDB
25.017 98
33.775 107
28.247 95
29.699 103
26.697 93
28.938 95
23.737 133
26.219 91
23.566 93
25.56 92
--------------------------------------------------------
Average in m/sec 27.1455 100
** PERFORMANCE INCREASE OF 72.85% **stress testing

for stress testing i opted to use new relic in conjunction with loader.io
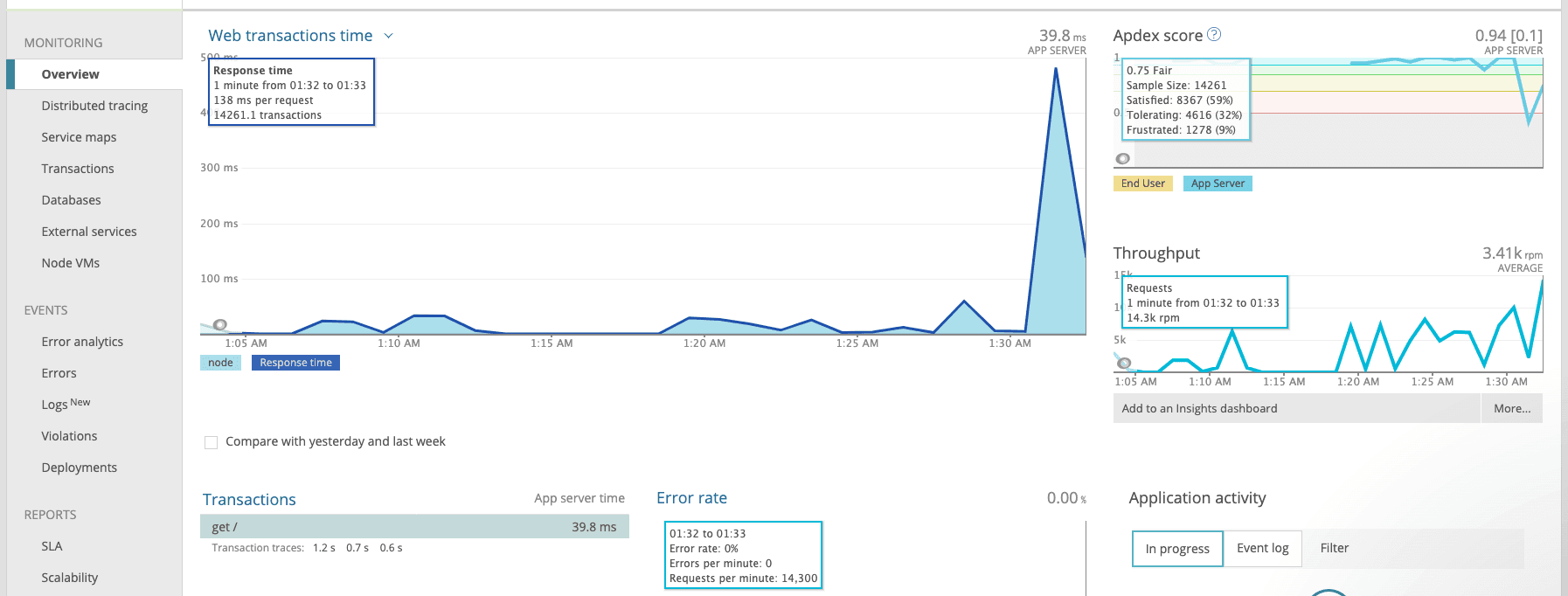
postgresQL
mongoDB
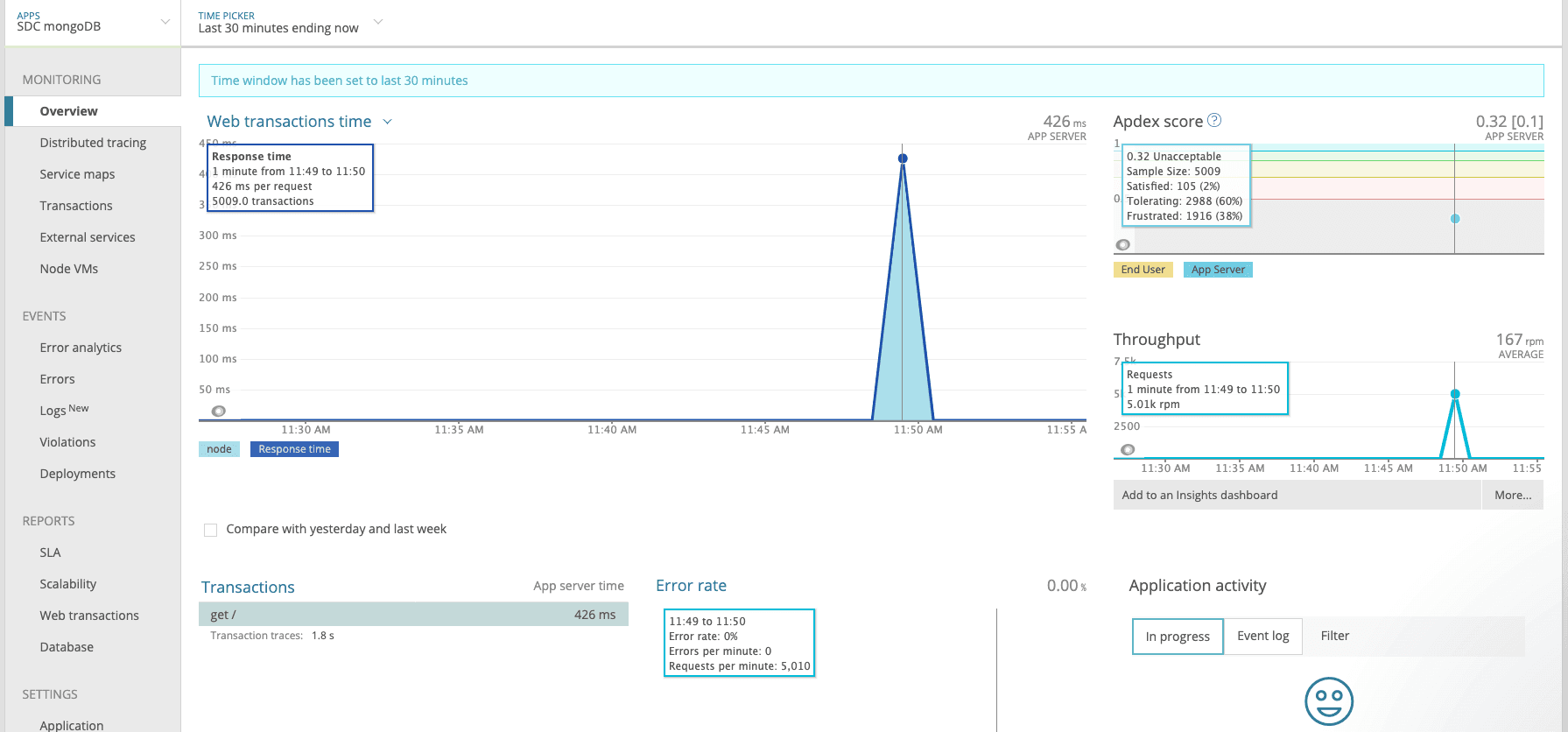
as they say, the proof is in the pudding. it was evident that postGres’ throughput was far outperforming mongos. we got our database
optimizing
with speed being of utmost importance, indexing played a huge role in the lowering querying times.
side note: wrong indexes can significantly slow down performance. But even the indexes that provide better performance for some operations, can add overhead for others eg. post, delete.
having inherited the related section, i realized my queries could either pull from the collections column or the category column. this lead me to test both columns with the appropriate indexing
explain analyze select * from related where gender = ‘w’ and category = ‘capris’ order by _id desc limit 50;
PostgresQL - query on gender and category
--------------------------------------------------------
26.906
26.47
27.095
24.736
27.337
26.582
19.35
28.65
28.242
27.297
--------------------------------------------------------
26.2665 Average in m/secexplain analyze select * from related where gender = ‘m’ and collections = ‘ABC’ order by _id desc limit 50;
PostgresQL - query on gender and collections
--------------------------------------------------------
0.292
0.286
0.16
0.239
0.166
0.133
0.235
0.238
0.239
0.237
--------------------------------------------------------
0.2225 Average in m/secwe got a winner
deploying to aws
the whole point of systems design is getting applications to scale. as such there are 2 main methods, horizontally scaling and vertically scaling. in simple terms, if you have the $, vertically might be more efficient as you’re basically throwing money at the problem eg. increasing hardware, ram, CPU’s, etc… whereas horizontal scaling is adding more instances and connecting them together to accomplish the same feat.
the short of it is
RICH - VERTICALLY SCALE
POOR - HORIZONTALLY SCALE
Have $1,000,000? - CALL ORACLE AND THEY EVEN SEND YOU A TECHNICIAN
being in the later, we opted for the free-tier on AWS. This gets us a t2.micro with 1gb of ram and 30gbs of hardware space.
devops is always a joy. the biggest joy is from the pain of security groups - inbound rules and outbound rules.
to whoever is reading this, let me make your life easier
and in the end it looks like
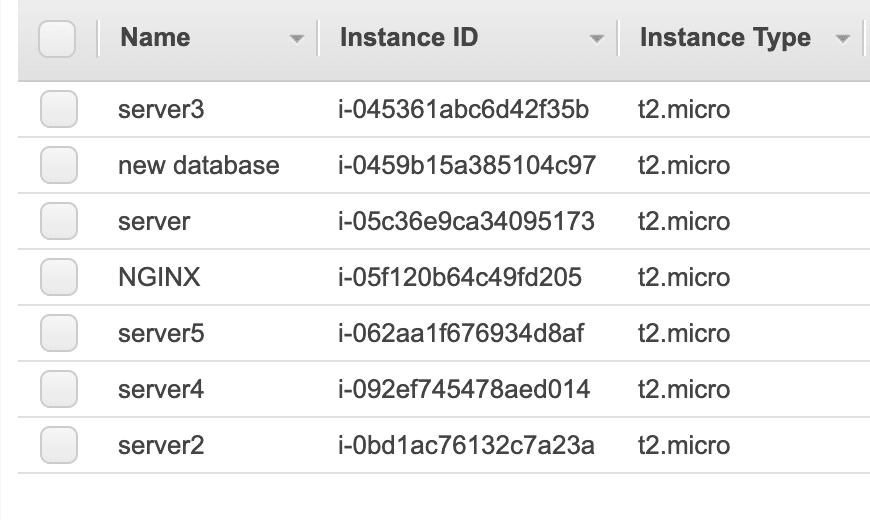
and hopefully this
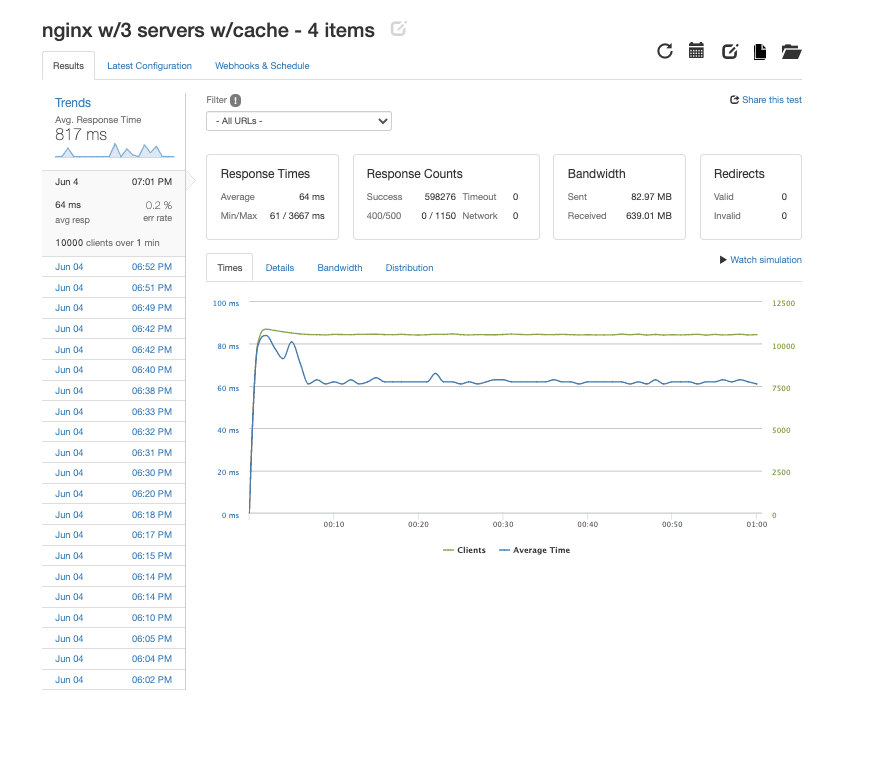
handling 10k like it’s a monday